Azure Blob Container data source
Pulling data directly from an Storage Account on Azure is a very efficient way of ingesting data into LinXmart, particularly when LinXmart itself is hosted within an Azure environment.
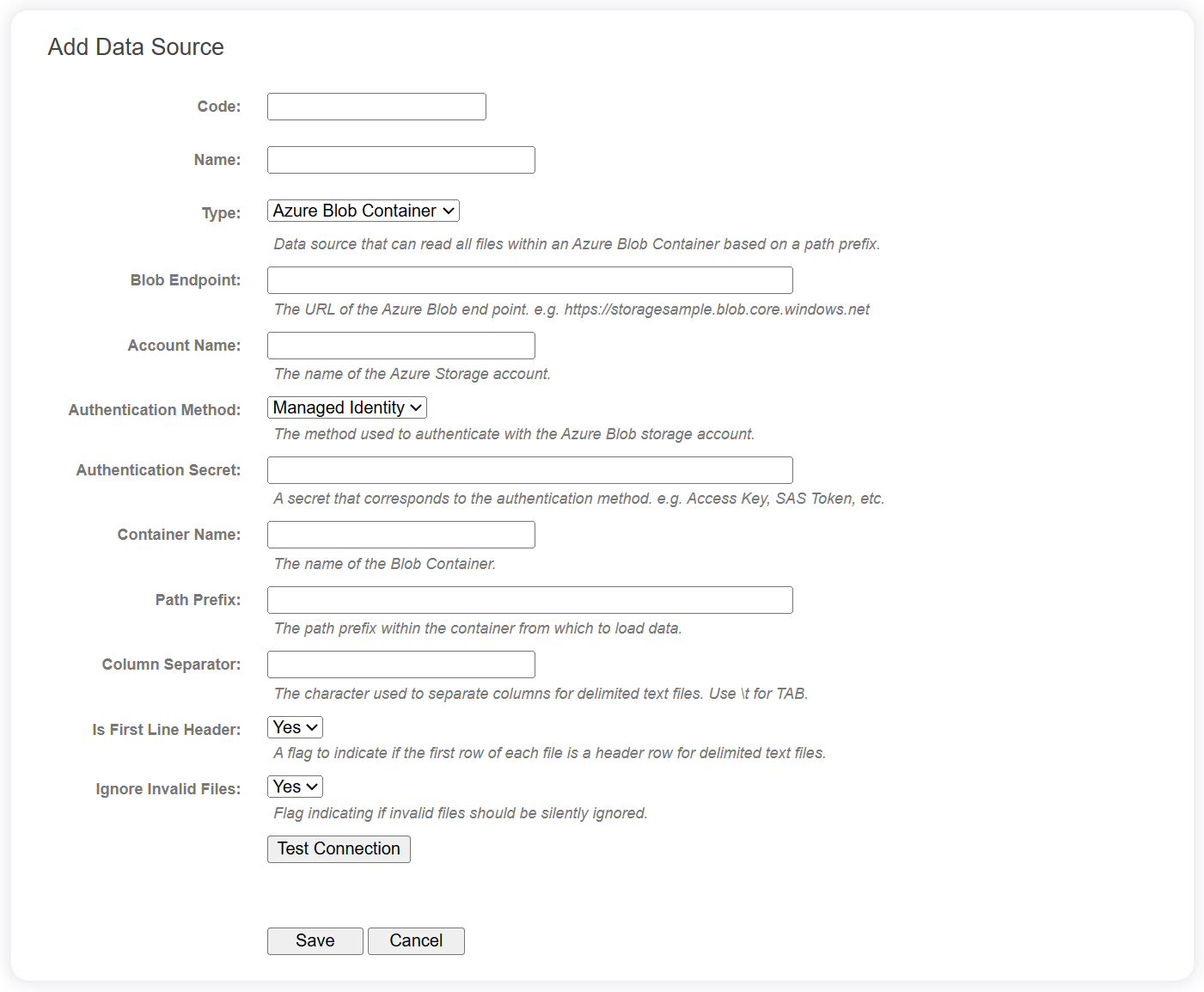
The following fields are required for Azure Blob Storage data sources.
| Field | Description |
|---|---|
| Blob Endpoint | The URL of the Azure Blob end point. e.g. https://[accountname].blob.core.windows.net |
| Account Name | The name of the Azure Storage account. |
| Authentication Method | The method used to authenticate with the Azure Blob storage account:
|
| Authentication Secret | A secret that corresponds to the authentication method. e.g. Access Key, SAS Token, etc. |
| Container Name | The name of the Blob Container. |
| Path Prefix | A simple path prefix within the container from which to load data. For example, specifying a path prefix of 'xxx/yyy' will search the container for all Blobs that begin with 'xxx/yyy'. |
| Column Separator | The character used to separate columns for delimited text files (use \t for TAB). This is only applicable for delimited text files. |
| Is First Line Header | A flag to indicate if the first row of each file is a header row. This is only applicable for delimited text files. |
| Ignore Invalid Files | Flag indicating if invalid files should be silently ignored. |
Use the Test Connection button to verify the Azure Blob Container can be reached using the configuration provided.
A system-wide setting (Data Source Configuration | Text File Data | Exclusion List) provides a set of glob patterns for excluding files and folders from any data source that searches for files within a folder hierarchy. This defaults to excluding any file or folder beginning with an underscore or a dot.
Supported file types
When blobs are enumerated using the data source configuration above, the extension of the blob is used to determine how to process the file.
If the blob file extension is .gz or .gzip, gzip compression is assumed and the system will attempt to decompress the file before parsing.
If the blob file extension is .parquet, the Parquet format will be assumed and data will be loaded using Parquet.
For all other extensions, the system will assume it is a delimited file and will use the Column Separator and Is First Line Header properties to determine how to parse it.
Gzip compression can be combined with any file, so all of the following file formats are supported:
- data.csv
- data.parquet
- data.csv.gz
- data.parquet.gzip