Defining matching strategies
LinXmart utilises a probabilistic linkage engine. This engine uses a 'match configuration' that tells it how to compare records, and when to designate two records as a match. Each Linkage Project has a separate match configuration, and a Linkage Project’s match configuration can be modified at any time. After modification, all future linkages will use the new match configuration, while previous linkages will not change.
To appropriately modify the match configuration, it is important that the operator has some understanding of probabilistic record linkage.
The default config
Each new Linkage Project will be created with a default match configuration. Operators can modify the configuration for each Linkage Project through the web UI if and when required. The default strategy has been designed to cater for a wide variety of administrative type datasets, so should give accurate results out of the box. However, all data is different, and as you develop a better understanding of your data and probabilistic linkage, you may benefit from changing this over time.
The default matching strategies for all new Linkage Projects can be configured at a global level. Set this default to suit your most common data matching scenarios.
Match strategies
The match configuration consists of one or more strategies. Each strategy must have one or more blocking fields and (optionally) a list of matching fields, the latter of which have associated comparison types and matching/non-matching probabilities. Each linkage strategy has its own threshold value associated with it.
Blocking
Blocking is an indexing technique that is used to reduce the number of comparisons required for a match strategy. Comparing every record to every other record is not always practical, so defining a a set of fields that can reduce the comparisons space is desirable. Each strategy defines a set of fields to block on before records are compared.
As an example, LinXmart’s default match configuration has two linkage strategies with different blocks. The blocks for these strategies are:
- Strategy 1:
Date of BirthandSex - Strategy 2:
Soundex of SurnameandInitial of Given Name
During the match processing, the first strategy will only compare records with the same Date of Birth and Sex. The second strategy will only compare records with the same Soundex of Surname and Initial of Given Name. This gives very high coverage of the desirable comparison space.
Deterministic strategy
A deterministic strategy is one based on a defined set of equal fields. For example, if two records have the same jurisdictional linkage key value, match them together. A deterministic strategy is one that has no matching fields defined, only blocking fields. These blocking fields are used to deterministically match all records together within the same blocks.
A deterministic strategy does not use the Threshold value that is defined.
Probabilistic strategy
A probabilistic strategy uses conditional probabilities to determine the likelihood that particular records belong to the same entity. Matching fields can be defined for each linkage field, with a comparison type and conditional probabilities that determine how weights for agreement and disagreement are determined.
During the matching process, a comparison between two records will involve comparisons for each matching field defined in the strategy. The sum of each field level comparison will be summed to produce an overall score for the record comparison. The Threshold value is used to determine whether the record comparison results in a matching pair (the score is greater than or equal to the threshold value), or whether it is discarded.
Strategy configuration
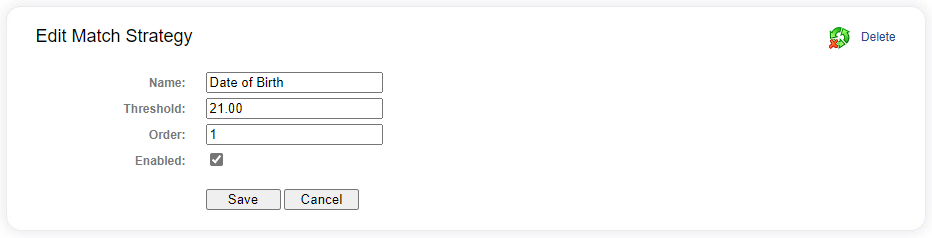
Each match strategy has a number of fields that can be modified as required.
| Field | Description |
|---|---|
| Name | A descriptive name given to the strategy for identification by an operator. |
| Threshold | The value used to determine if a record comparison is classified as a match. If the score from the record comparison is at least as much as the threshold value, it results in a matched pair. |
| Order | The order in which this strategy is run against the other strategies in the match configuration. Two records will not be compared if a previous strategy has already classified them as a match. |
| Enabled | A flag indicating if this strategy will be used. |
Put your deterministic strategies first in order, as these will run faster than probabilistic comparisons.
Blocking fields
Each blocking field is combined to produce discrete sets of records to compare during the match processing. The more fields added here, the smaller the size of the record sets. Smaller record sets produces less comparisons, so they are more likely to be matches, but potentially miss out on other record pairs that could be matches.
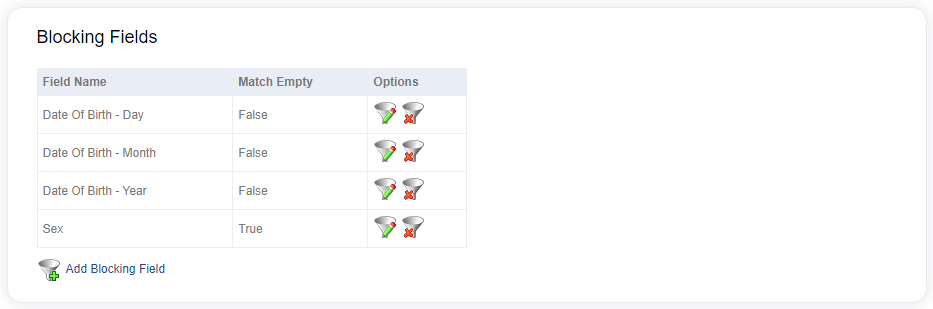
In addition to specifying the linkage field, you can specify whether to include empty values (Match Empty). Setting this to True will include null or empty values in the set of acceptable value combinations. This will only allow you to compare records that both have that value set to null.
Matching fields
There are several ways to add matching fields to a strategy. LinXmart allows the operator to add matching fields one by one, to choose the default matching fields defined in LinXmart, or to copy the matching fields from a previously created strategy, if one exists.
To add the default matching fields, click the Add Default Matching Fields link below the Matching Fields section when editing a strategy. To copy the matching fields from the previous match strategy (in terms of its order), click the Copy Matching Fields from Previous Strategy link.
To add matching fields individually, click Add Matching Field from this pane. The following fields are presented:
| Field | Description |
|---|---|
| Name | The linkage field to be compared. A drop-down box allows for selection from the available fields. |
| Comparison | The type of comparator to be used. Options available depend on the linkage fields selected. Available options are listed below. |
| Match probability | Also known as the m-probability. The estimated probability that two records belonging to the same person have the same value of this linkage field |
| Non-match probability | Also known as the u-probability. The estimated probability that two records belonging to different people have the same value of this linkage field |
| Agreement weight (override) | The score to be given if two records have the same value of this linkage field. If a value is entered here, the match and non-match probabilities are ignored. |
| Disagreement weight (override) | The score to be given if two records do not have the same value of this linkage field. If a value is entered here, the match and non-match probabilities are ignored. |
| Weight curve | Weight curves are used to convert the score found from an approximate comparison type (such as the Jaro-Winkler string comparator function or the several available Bloom filter comparison methods) to a score that lies somewhere between the agreement and disagreement weight. LinXmart provides several weight curve options, one for each approximate comparator type. In nearly all circumstances, the weight curve associated with the string-matching comparator should be used. For exact matching or other non-approximate approaches, this can be left as (none). |
Comparison types
Exact
This compares the two fields values as strings and if they are exactly the same, they are assigned the field’s Agreement Weight. If they are in any way different, they are assigned the Disagreement Weight. These are the only two possible weights that can be assigned.
Jaro-Winkler
Jaro-Winkler is a string similarity algorithm designed for use with names. Compared values that are not exactly the same but are very similar will be given a high weight, with those less similar given a lower weight. These weights will be in between the agreement and disagreement weight for this field.
Numerical (Year)
This compares years as numbers with some tolerance in matching. The comparator computes the difference in years relative to a base year (the year in which the Linkage Project was created). If the minimum value is less than 20 years from the base year and the values differ by no more than a year, then the full agreement weight is assigned. If the minimum value is 20 years or more from the base year and the values differ by no more than 2 years then the full agreement weight is assigned. Otherwise, the weight is linearly interpolated between full agreement and full disagreement weights with a slope proportional to |year1 – year2|/min(year1,year2).
Strict Numerical
This converts the field values to integers before comparing them as numbers with a tolerance of +/- 1. E.g. 11 will match 12. Also, field values like ‘0009’ and ‘9’ will match (whereas they would not have in an exact string comparison). Full agreement and disagreement weights are the only two possible weights that can be assigned.
String Contains
This comparison will look for the existence of one field value within the other record. This is a bidirectional check. If one of the values exists within the other, full agreement is returned, otherwise full disagreement is returned.
Hierarchical String Contains
The comparison allows each side of the field comparison to have a delimited list of ‘hierarchical’ strings. When the comparison runs, only one value in the delimited lists of each side needs to match. The ‘hierarchical’ part means that each item in the list represents a value or code that can be broken down into hierarchies. For example, Canadian postcodes have two levels of hierarchy – the first 3 characters represents a wide geographic region (the forward sortation area (FSA) code) and the last 3 characters represents a local region within it. So, when each item in the delimited lists is compared, the levels within the hierarchies are checked. The first hierarchy achieves full agreement weight. The last hierarchy achieves a weight half-way between disagreement and agreement. The remaining hierarchies are even distributed between.
This comparison has two parameters: Value Levels and Delimiters. Value Levels is a delimited list of hierarchies in the field. Zero means the entire string is checked. A positive value refers to the first n characters. A negative value refers to the last n characters. The Delimiters field defines the characters used to separate the Value Levels as well as the values in the fields.
Bloom Field (Dice)
This comparison type is used for comparing Bloom filters. It computes the Dice coefficient, allowing string similarity matching to occur on encoded data fields. This comparison is only available for binary fields.
Bloom Field (Hamming)
This comparison type is used for comparing Bloom filters. It computes the Hamming distance, allowing string similarity matching to occur on encoded data fields. This comparison is only available for binary fields.
Bloom Field (Jaccard)
This comparison type is used for comparing Bloom filters. It computes the Jaccard distance, allowing string similarity matching to occur on encoded data fields. This comparison is only available for binary fields.
Hierarchical Bloom Field Contains
This works similarly to the String version with the exception that it is only 1 to many, not many to many. That is, one side of the comparison can only have a single item; the other side can have a list of items. This works on the same premise as the Hierarchical String Contains comparator in that you specify the Value Levels and Delimiters as part of the transform.