Merge vs best-link grouping
The matching process performed by LinXmart results in a number of matching pairs that represent weighted likelihoods between different records. In order to create sets (or groups) of records that represent individual entities, these pairs need to go through a grouping process. By default, LinXmart uses a merge-based grouping strategy.
Merge grouping
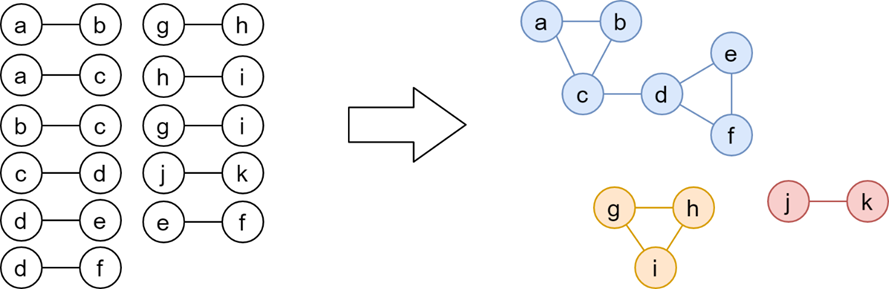
The merge grouping process involves amalgamating all record-pairs together. Records belong to the same person if they are directly connected (i.e. there is a record-pair that joins them together) or indirectly connected (i.e. through other connected records). While records B and E did not form a pair through linkage, they are indirectly connected, through records C and D, and so are classified as the same person.
Weighted best-link grouping
LinXmart also includes an alternate grouping approach which in certain circumstances can improve linkage quality, known as weighted best-link grouping. Weighted best-link grouping is similar to merge-based grouping, but with one key difference; existing groups in the Linkage Project cannot be merged together by incoming records. Depending on the associated pairs found, a new record may join an existing group, or form a new group. A new record cannot cause the merging of two or more existing groups.
Pairs are processed in descending weighted order, beginning with any pair created from a deterministic match strategy. Any pairing that would result in the merging of two existing groups is ignored. Here is an example:
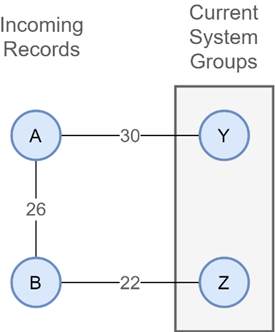
Here the pair A-Y is processed first as it has the highest confidence score, resulting in record A joining record Y’s group. The pair A-B is processed second, resulting in record B also joining record Y’s group. Pair B-Z is processed last and because record B is already a member of Y’s group, this pair is ignored.
If a new record does not match to any existing record, then it will form its own group. In future linkages using this grouping strategy, it will not be able to 'merge' with other existing groups.
Unlike Merge based grouping, with Weighted best-link grouping, the order in which envelopes of records are processed can influence the final groupings that are formed.
When a record is deleted under Weighted best-link grouping, all remaining records in the group are then re-grouped, as if they have just arrived into the system for the first time. These records then have the opportunity to join to any existing group but not to merge existing groups.
While deleting a record under Merge grouping will result in the same group structure that would have existed had that record never entered the system, this is not necessarily the case with Weighted Best-Link grouping.
Weighted best-link grouping is particularly useful when linking against a pre-existing repository of linked records for which you have confidence in their linkage quality. Weighted best-link grouping essentially allows you to leverage this pre-existing quality; whenever an incoming record attempts to join two pre-existing groups together, as we have confidence in the current groups, under this grouping strategy this join is ignored.
Grouping configuration
The grouping configuration is set for each Linkage Project. The grouping configuration can be changed at any time – upon modifying, all future linkages will use the new configuration, while past linkages will remain unchanged.
To view or edit the group configuration for a Linkage Project, open the Project Details page by selecting the Linkage Project from the PROJECTS tab. From here, click Group Config from the options in the top right of the pane. The View Grouping Configuration page will appear, showing the current grouping strategy for the project. By clicking the Edit button in the top right of the pane, the operator can edit this configuration.

For each of the 'merge' and 'best-link' grouping types, you can choose whether it is disk based or in-memory. Disk based will use local disk on the server to cache the groups during processing. In-memory will use a memory based cache. In-memory will be faster, but should be selected with care as very large linkage projects may consume large amounts of memory.
You can start with in-memory grouping and monitor the server's usage over time to understand how your data affects resources on the server.